An earlier blog entry showed how to integrate MQ with the Prometheus database, capturing statistics that can then be shown in a Grafana dashboard. In this article, I’ll show how that initial work has been extended to work with more databases and collection tools.
The latest updates allow MQ to write directly to InfluxDB and OpenTSDB databases, and also to provide data to collectd.
The MQ programs
All of the MQ programs discussed here are in the same github repository. Cloning that repository gives copies of all of the MQ source code, configuration scripts, and example Grafana dashboards.
The main change from the original Prometheus-only solution has been to separate common code into a Go package (mqmetric), leaving a relatively small amount of monitor-specific code to handle configuration and how to write data to the database. The monitor programs are in individual subdirectories of the cmd tree – mq_coll, mq_influx, mq_opentsdb and mq_prometheus – and can be compiled with the go build command. README files in each subdirectory show any special configuration needed.
InfluxDB and OpenTSDB
Both InfluxDB and OpenTSDB are examples of time-series databases. Entries in the databases consist of a timestamp, metric name, value, and optional tags. The MQ metrics are created with a tag of the queue manager name, and (for the queue-specific elements) the object name. Those tags enable queries to be made that show the current status for sets of resources.
Configuring the monitor program
The main programs are all intended to be started from a shell script. The script itself is also included in the source tree. Put the script in a suitable directory (for example, /usr/local/bin/mqgo) and make sure it is executable by the mqm id. Edit the script to provide parameters for the main program. Required parameters include the address of the database, any userid and password information required to connect to that database, and the list of queue names which you want to monitor. In these scripts, the password is given as a hardcoded string, but you would probably want to change that to extract it from some other hidden file.
The monitor always collects all of the available queue manager-wide metrics. It can also be configured to collect statistics for specific sets of queues. The sets of queues can be given either directly on the command line with the
-ibmmq.monitoredQueues flag, or put into a separate file which is also named on the command line, with the -ibmmq.monitoredQueuesFile flag. An example is included in the startup shell script. For example,
mq_influx -ibmmq.QueueManager="QM1"
-ibmmq.monitoredQueues="APPA.*,APPB.*"
starts the monitor to collect the statistics for all queues whose names begin APPA and APPB.
For InfluxDB, the name of the database into which the data will be written is also required. You may want to create an MQ-specific store to keep these statistics separate from others. No database name is needed for OpenTSDB; the data is written to the single store.
Configuring MQ
An MQSC script is included in the monitor’s source directory, which defines a shell script as an MQ service. Edit the MQSC file to point at the directory where you have set up the script that will get run, and then apply it through runmqsc.
The monitor should start immediately, and on every subsequent queue manager restart. if there are problems, they should be reported in the output of the service program which is sent to a location defined in the MQSC script.
Grafana queries
One key visible difference between the different time series databases is how queries are constructed in Grafana, and creating the content for the legend. The principles are similar, but the query editor varies slightly depending on the datasource, and the way in which tags are exposed.
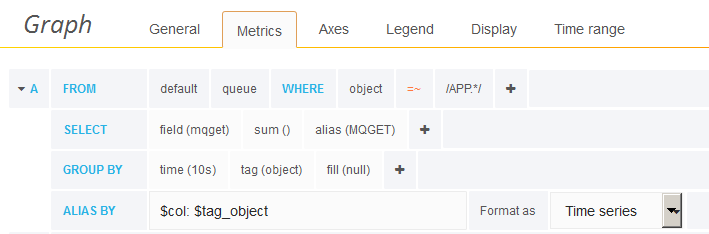
This picture shows the Grafana query editor for InfluxDB, selecting data about queues that match the “APP.*” pattern. The selected field name (mqget) is the metric as reported from MQ, and it is then given an alias of MQGET. Using the alias in the SELECT component allows us to reference $col in the ALIAS BY line. Similarly, using tag(object) in the GROUP BY line allows use of $tag_object in the ALIAS BY line. Combining these gives a legend for all of the lines shown in the graph, MQGET: APP.0 MQGET: APP.1 and so on, without needing to explicitly name each queue.
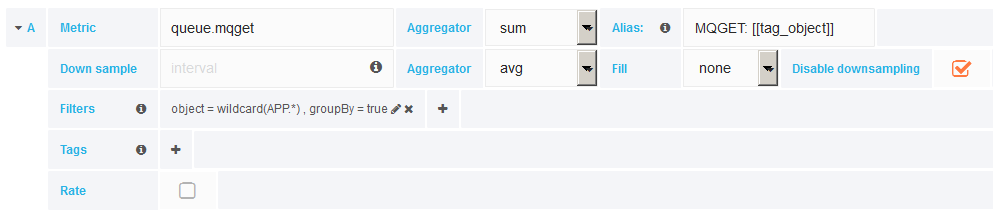
The Grafana editor for data held in OpenTSDB, extracting exactly the same information, looks like this:
Collectd
The integration with collectd follows a different pattern than the integration with the previously-discussed databases. Instead, collectd is more like a controller and router, calling plugins to ask for metrics for their components, and calling other plugins that write the metrics to a range of data stores. The data store might be something as trivial as a flat file, or it might be another database. The metric-providing plugins (MQ in this case) are unaware of how the data is forwarded and stored, analagous to a publish/subscribe system.
Configuring collectd
The collectd system needs to be told two things: how to invoke the MQ collector, and which metrics MQ provides. A short configuration file, provided in the github tree as mq.conf, can be dropped into the collectd configuration directory (typically /etc/collectd.d) for this. It causes collectd’s exec interface to call the shell script – make sure the configuration file is pointing at the correct directory – and loads the list of metrics generated by MQ. The shell script also has to be modified, similarly to the previous examples, to give the list of queues to be monitored, and again to point at the correct directory. The MQ program simply writes data to stdout, where the metrics are collated and sent to whichever backend has already been configured in collectd. Once the configuration file has been updated and put in place, restart collectd so that it reads the new configuration.
On my system, I had set up collectd to route data to Graphite, another database. Grafana knows how to query information from Graphite and so adding it as a further datasource allows formatting of the MQ statistics.
Here is a similar query as shown above, this time to pull data from Graphite:

The default configuration for graphite on my collectd system adds the string “collectd” at both the front and back of the machine hostname; that seems a bit much but it does make it clear where the data is coming from. It is visible in this query string. Another difference from the other examples is that each data point with collectd contains the queue manager and queue name as part of the overall metric name instead of being tags on more generic data points. That means that there does not seem to be quite the same level of field replacement for the legend, at least when showing it in Grafana, but it is still usable. There are also constraints on where wildcards appear in the query, so this is showing information for all queues instead of just the “APP.*” names. There may be better filtering possible, but I could not find it easily in the Grafana query editor. Some of the output plugins for collectd may also support rewriting of the metric name to split out fields that can be used as tags.
There is no MQ configuration needed here; the collection program does not run as an MQ service as it is started and stopped under the control of collectd.
Summary
This picture brings together all the Grafana dashboards for the different collectors. The same metrics are shown in each dashboard.
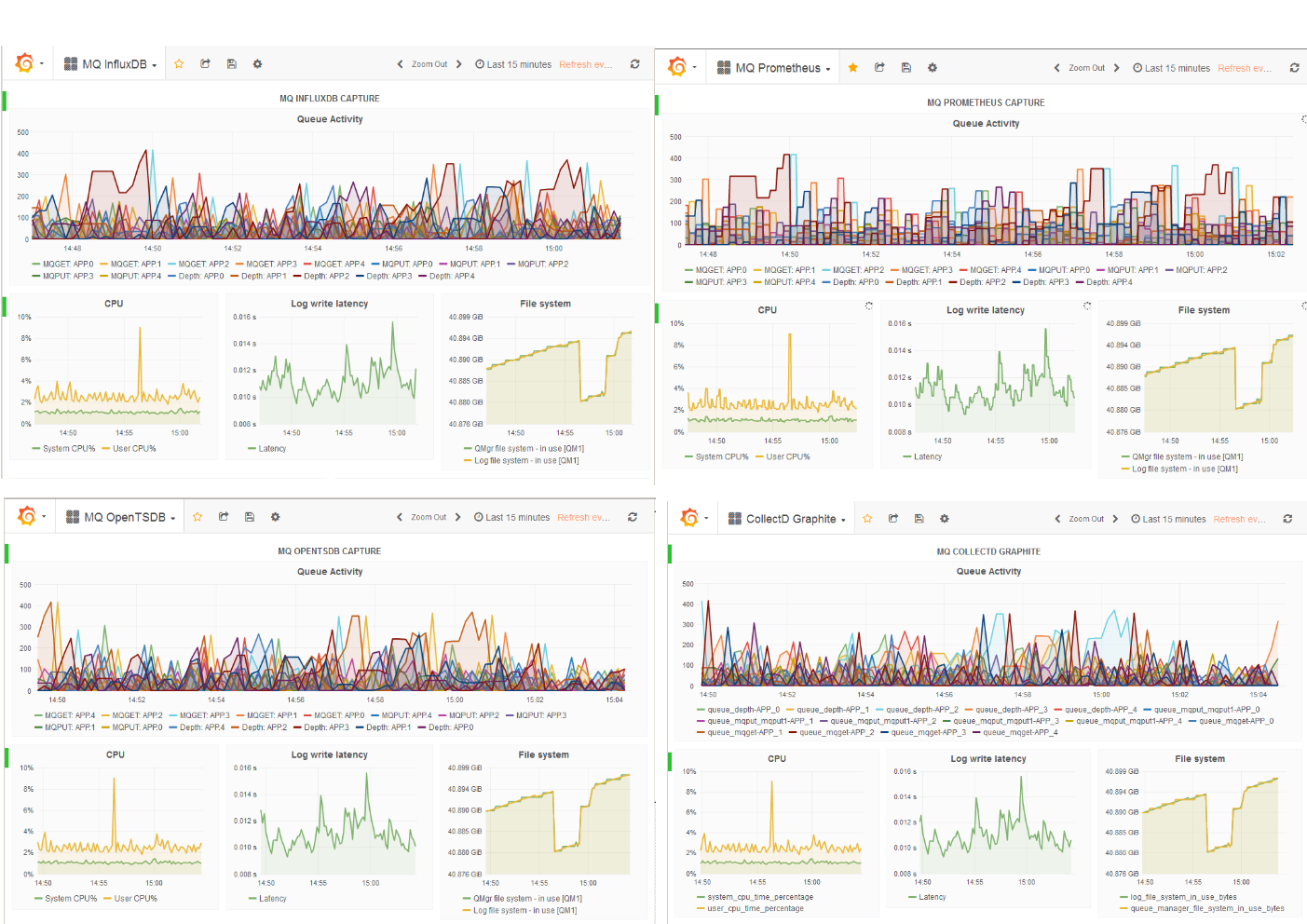
From this, we can see how a variety of monitoring solutions can be used with MQ. This follows the philosophy that MQ has had for all its lifetime – it will not enforce a particular implementation of an aspect on you, whether that’s operating system, programming language or management tool. Instead it tries to work with whatever you are already comfortable using. These open-source solutions are popular for monitoring other components of IT infrastructures, and it makes sense to integrate MQ into those same designs.
This article and the associated code has shown how it can be done.
This post was last updated on November 27th, 2021 at 03:00 pm