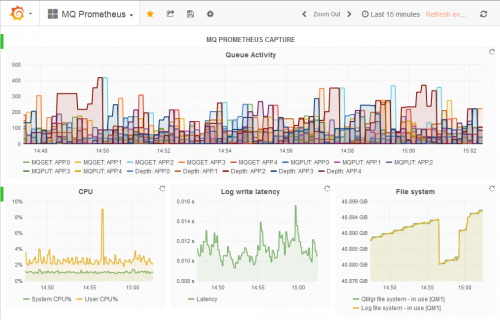
The mq-metric-samples collectors that send IBM MQ metrics and status data to a range of databases, ready to be viewed in Grafana, have just been enhanced to collect additional information. The Prometheus collector has also been extended so that it can continue providing limited status even when the queue manager is down.
The new metrics have all been suggested by users of the package either directly or via issues raised in the GitHub repository. Many previous articles on here show more about the collectors.
The InfluxDB collector is also refreshed for a new version of the database.
Continue reading “New features with the MQ Go metric collectors”This post was last updated on November 27th, 2021 at 02:59 pm